sql之互相关注的人
第一种:单向关注,比如A关注B,但是B没有关注A,同时A关注B的同时A也关注了C,但是C没有关注A。像这类单纯的左边关联右边,称之为单向关注。第二种,双向关注,A关注了B,B也关注了A。
也就是说左边关注右边的同时,右边也关注了左边,称之为双向关注。当关注为双向时数据如下,A–>B,B–>A,通过规律可以发现,如果将A–>B或者B–>A调换位置,那么聚合之后一定是双数并且是2,
当关注为单向时不会出现双数,只会出现单数。
一、建表初始化数据
create table follow_each_others
(
from_side VARCHAR(20)
,to_side VARCHAR(20)
)
select * from follow_each_others
insert into follow_each_others values
(‘宇智波带土’,’漩涡鸣人’)
,(‘宇智波带土’,’波风水门’)
,(‘波风水门’,’宇智波带土’)
,(‘宇智波佐助’,’宇智波带土’)
,(‘漩涡鸣人’,’日向雏田’)
,(‘日向雏田’,’漩涡鸣人’);
二、分析我要的结果,互相关注
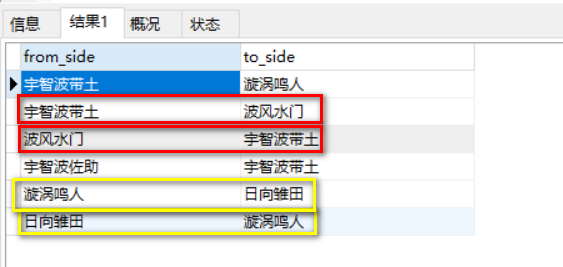
三、编写相关的sql
select
u1.from_side,
u1.to_side
FROM
follow_each_others u1 join follow_each_others u2
on u1.from_side=u2.to_side and u1.to_side=u2.from_side;
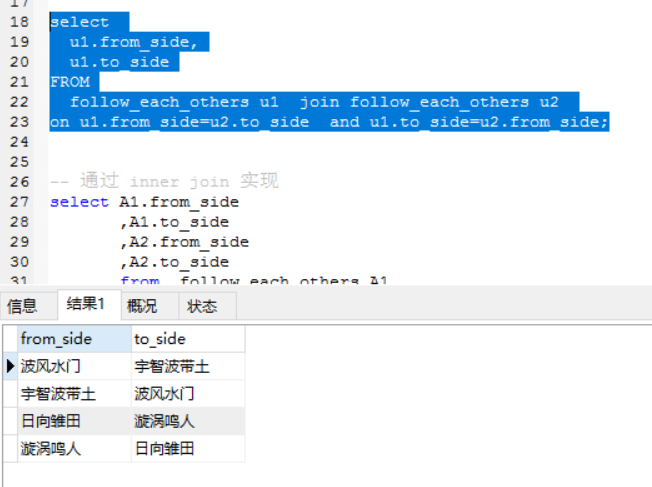
— 通过 inner join 实现
select A1.from_side
,A1.to_side
,A2.from_side
,A2.to_side
from follow_each_others A1
inner join follow_each_others A2
on A1.from_side = A2.to_side
AND A1.to_side = A2.from_side
where A2.from_side is not null
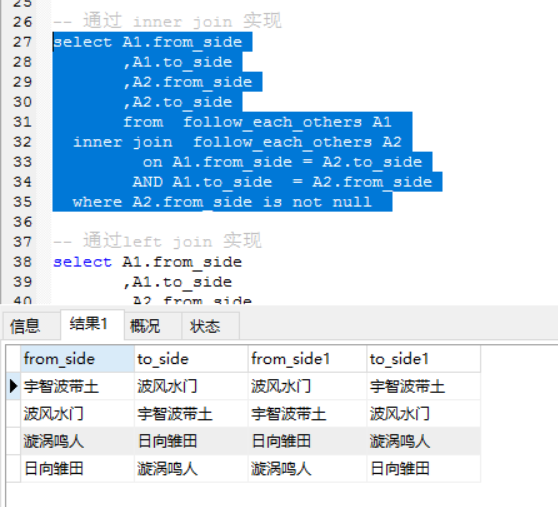
— 通过left join 实现
select A1.from_side
,A1.to_side
,A2.from_side
,A2.to_side
from follow_each_others A1
left join follow_each_others A2
on A1.from_side = A2.to_side
AND A1.to_side = A2.from_side
where A2.from_side is not null
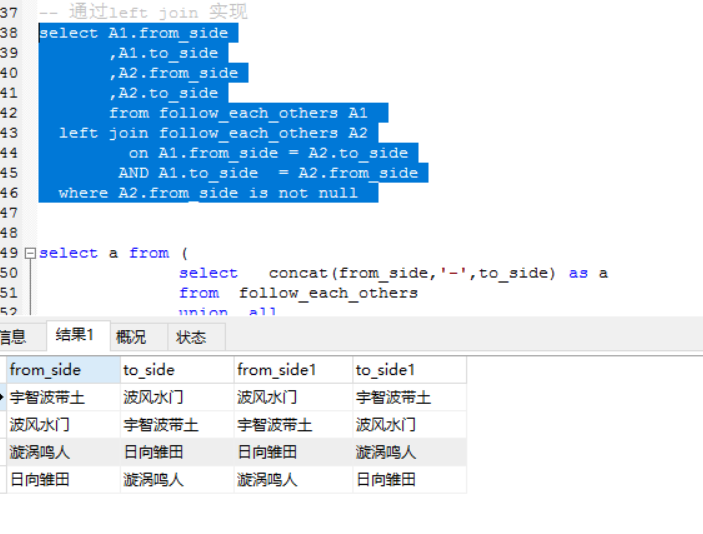
select a from (
select concat(from_side,’-‘,to_side) as a
from follow_each_others
union all
select concat(to_side,’-‘,from_side) as a
from follow_each_others
) t
group by a having count(1)>1
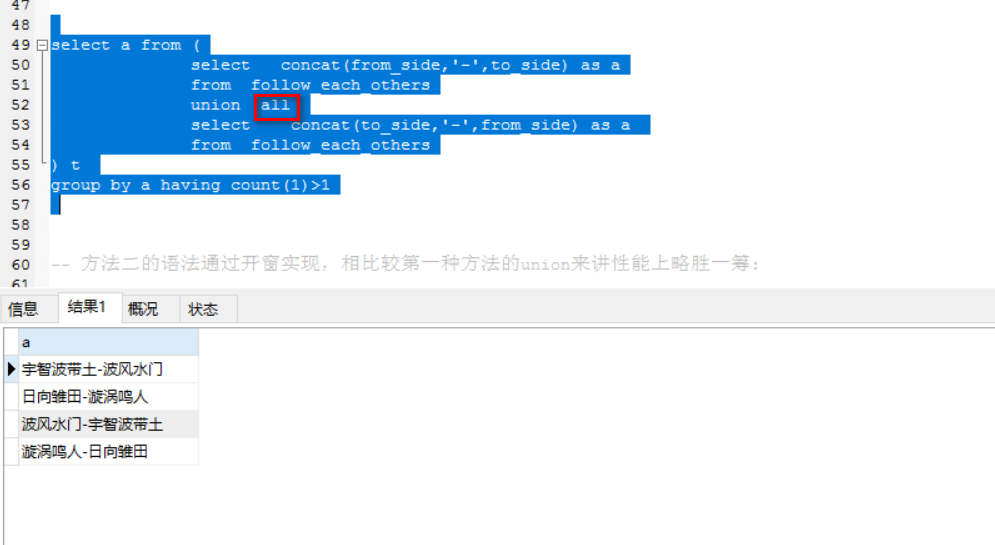
缺少Union ALL结果差一截
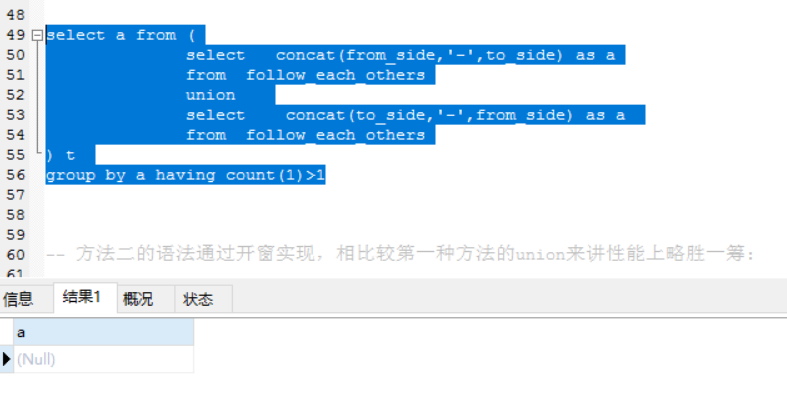
Union all 与Union区别
MySQL UNION和UNION ALL都是用于将多个SELECT语句的结果组合成单个结果集的查询语句,但它们之间存在一些重要的区别。
UNION操作符返回不重复的行,而UNION ALL返回所有行,包括重复行。
UNION操作符需要MySQL在执行操作之前进行额外的工作,以消除重复的行,这可能会导致查询的执行速度较慢。而UNION ALL不需要这样的额外工作,因此可以更快地执行查询。
以下是一些使用MySQL UNION和UNION ALL的示例:
- 使用UNION组合两个表的结果集,并返回不重复的行
SELECT column1 FROM table1
UNION
SELECT column1 FROM table2;
此查询将返回table1和table2中所有不重复的column1值。
- 使用UNION ALL组合两个表的结果集,并返回所有行,包括重复行
SELECT column1 FROM table1
UNION ALL
SELECT column1 FROM table2;
此查询将返回table1和table2中所有的column1值,包括重复的行。
请注意,在处理大量数据时,使用UNION ALL比使用UNION更快,因为不需要消除重复的行。但是,如果您需要返回不重复的行,则必须使用UNION操作符。 作者:学为先编程 https://www.bilibili.com/read/cv22890451/ 出处:bilibili
百度推荐答案
— 方法二的语法通过开窗实现,相比较第一种方法的union来讲性能上略胜一筹:
select from_side
,to_side
,follow_each
from (
select from_side
,to_side
,follow_each
,count(1) over(partition by follow_each) as cnt
from (
select from_side
,to_side
,if(from_side>to_side ,concat(from_side,’-‘,to_side),concat(to_side,’-‘,from_side)) as follow_each
from follow_each_others
) a1
)a2
where a2.cnt>1